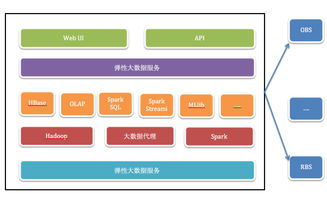
在當今數據驅動的時代,彈性大數據架構已成為企業應對海量、多源、實時數據挑戰的核心解決方案。其核心優勢在于能夠根據負載動態伸縮資源,實現成本與性能的最優平衡。本文將通過一張架構圖,為您清晰解析彈性大數據架構中數據處理與存儲服務的關鍵組件與流程。
架構全景圖核心層次
一張典型的彈性大數據架構圖通常自上而下分為四層:數據攝入層、數據處理與計算層、數據存儲層以及統一管理與調度層。各層通過彈性云服務無縫銜接,共同構成一個靈活、高效的數據價值鏈。
數據處理服務:流批一體的計算引擎
在數據處理層,彈性架構的核心是計算與資源分離。計算服務(如Spark、Flink處理集群)與底層資源(虛擬機、容器)解耦,通過Kubernetes等容器編排平臺實現秒級彈性伸縮。
- 實時流處理:采用Flink、Spark Streaming等引擎,對消息隊列(如Kafka)中的數據進行實時過濾、聚合與風控分析,結果可實時寫入數據庫或送至下游應用。
- 批處理與數據湖分析:利用Spark、Hive on Tez等引擎,對存儲在對象存儲(如S3、OSS)或數據湖中的歷史數據進行ETL清洗、復雜分析與機器學習模型訓練。計算集群按需啟動,任務完成后自動釋放資源,實現成本優化。
- 交互式查詢:通過Presto、Impala等即席查詢引擎,為用戶提供對海量數據的亞秒級快速查詢能力,計算資源池可根據并發查詢量自動擴縮容。
數據存儲服務:分層、多模的彈性存儲
彈性架構的存儲層遵循“熱溫冷”數據分層策略,并采用多模存儲以適配不同數據類型與訪問模式。
- 數據湖存儲(核心存儲層):通常基于高可擴展、低成本的對象存儲(如AWS S3、Azure Blob Storage、阿里云OSS)構建企業級數據湖,存儲所有原始與加工后的數據,是批處理與分析作業的主要數據源。其無限擴展的特性是彈性的基石。
- 高速緩存與索引存儲:為滿足低延遲訪問需求,使用Redis、Memcached作為熱數據緩存;使用Elasticsearch提供全文檢索與日志分析能力。這些服務通常以托管集群形式提供,支持垂直與水平彈性伸縮。
- 實時/分析型數據庫:流處理結果或聚合后的數據可寫入云原生數據庫,如時序數據庫TSDB用于監控數據,分析型數據庫ClickHouse或云數據倉庫(如Snowflake、BigQuery、MaxCompute)用于支撐BI報表與即席分析。這些服務大多具備存儲與計算獨立伸縮的能力。
- 消息隊列與日志存儲:Kafka作為實時數據管道中樞,其托管服務(如MSK、Confluent Cloud)可平滑處理流量峰值。操作日志、審計日志可持久化至專為日志優化的存儲服務(如S3+Iceberg格式,或ELK套件)。
統一管理與調度:彈性的“大腦”
彈性調度由工作流編排器(如Airflow、AWS Step Functions)和資源管理器共同完成。它們監控隊列堆積、資源利用率等指標,自動觸發計算集群的擴容或縮容策略,并協調數據處理DAG中各個任務的依賴與執行。
核心彈性價值體現
通過上述組件協同,該架構實現了:
- 資源彈性:應對業務波峰波谷,避免資源閑置與瓶頸。
- 成本優化:采用按需付費與Spot實例等策略,顯著降低TCO。
- 敏捷開發:存儲與計算解耦,使數據團隊能獨立、快速地迭代數據處理邏輯。
- 架構韌性:云服務的多可用區部署與高可用設計保障了業務連續性。
###
總而言之,一張清晰的彈性大數據架構圖,生動展現了以對象存儲為中心的數據湖、彈性可擴縮的計算集群以及多樣化的數據存儲服務如何有機整合。它不僅是技術組件的羅列,更描繪了一條從數據流入到價值產出的高效、經濟且敏捷的彈性管道。企業構建此類架構時,應緊密結合自身業務場景,在數據處理時效性、存儲成本與查詢性能之間找到最佳平衡點。