在人工智能(AI)浪潮席卷全球的今天,數據處理及存儲服務已從后臺支持角色躍升為驅動AI技術創新與應用的核心引擎。AI系統,無論是簡單的分類模型還是復雜的自動駕駛算法,其智能的源頭與演進的養分均來自于數據。因此,圍繞數據的高效處理與安全存儲,構建起支撐整個AI產業發展的關鍵基礎設施。
一、數據處理:AI的“煉金術”
數據處理是AI生命周期的第一步,其目標是將原始、無序的“數據礦石”提煉為可供模型訓練的“信息黃金”。這一過程主要包含幾個關鍵環節:
- 數據采集與匯聚:AI系統需要海量、多源的數據。這包括從物聯網設備、社交媒體、企業業務系統、公開數據集中實時或批量收集結構化與非結構化數據。數據服務需提供高效的爬取、傳輸與接入工具,確保數據流的持續與穩定。
- 數據清洗與標注:原始數據常伴有噪聲、缺失值與不一致性。數據清洗通過去重、糾錯、格式化等手段提升數據質量。對于監督學習,數據標注(如圖像分類、語音轉文本、情感分析)至關重要,這催生了專業的數據標注服務產業,結合自動化工具與人工質檢,為模型提供精準的“學習材料”。
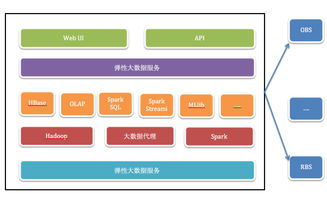
- 數據加工與特征工程:此階段將數據轉化為模型能更好理解的特征。包括數據轉換、歸一化、降維,以及通過領域知識構建新的特征。優秀的數據處理服務能提供強大的計算框架(如Spark、Flink)和可視化工具,幫助數據科學家高效完成這些任務。
二、數據存儲:AI的“記憶庫”與“糧倉”
經過處理的數據需要被妥善存儲,以備模型訓練、再訓練和推理調用。AI對存儲的需求呈現出獨特挑戰:
- 海量與可擴展性:AI項目往往涉及TB甚至PB級數據。存儲系統必須具備彈性伸縮能力,能夠根據數據量的增長近乎無限地擴展,云存儲服務在此方面展現出巨大優勢。
- 多樣性支持:AI數據格式多樣,包括文本、圖像、視頻、音頻、3D點云等。存儲系統需支持對象存儲、文件存儲、塊存儲及數據庫等多種形式,并能高效處理非結構化數據。
- 高性能與低延遲:模型訓練是計算密集型任務,需要存儲系統提供高吞吐量和低延遲的數據讀寫能力,以避免I/O瓶頸。分布式文件系統(如HDFS)、高性能對象存儲以及與計算引擎緊密集成的存儲方案成為標配。
- 成本與分層管理:考慮到數據熱度不同,智能分層存儲策略被廣泛采用。熱數據(頻繁訪問)存放于高速存儲(如SSD),溫數據存放于標準云存儲,冷數據(歸檔數據)則遷移至成本極低的歸檔存儲,實現成本與效率的最優平衡。
三、一體化服務趨勢與核心價值
當前,領先的云服務商(如AWS、Azure、Google Cloud、阿里云、騰訊云等)及專業數據平臺公司,正致力于提供數據處理與存儲的一體化、全托管服務。這些服務通常包括:
- 數據湖/數據湖倉一體:構建統一的數據存儲庫,容納原始和處理后的各類數據,支持大數據處理、機器學習與商業智能分析,打破數據孤島。
- 自動化機器學習(AutoML)平臺:集成數據準備、特征工程、模型訓練與部署,降低AI應用門檻。
- 專門針對AI優化的存儲實例:如配備高速GPU和NVMe存儲的計算實例,專為訓練任務優化。
- 強大的安全與合規保障:提供端到端加密、精細化的訪問控制、審計日志以及符合GDPR等法規的數據治理工具,確保數據主權與隱私安全。
###
人工智能的競爭,在底層是數據與算力的競爭。高效、智能、安全的數據處理與存儲服務,不僅為AI模型提供了高質量的訓練基礎,更通過簡化工作流程、降低技術門檻和總擁有成本,加速了AI從實驗室走向千行百業的進程。隨著邊緣AI、聯邦學習等技術的發展,數據處理與存儲服務將進一步向分布式、智能化、隱私保護的方向演進,持續夯實智能時代的數字基石。