隨著云計算技術的深入發展,云原生(Cloud Native)已成為構建和運行現代化、可擴展、高彈性應用的核心范式。它不僅僅是一種技術集合,更是一套系統的設計理念和方法論,旨在充分利用云平臺的彈性和分布式優勢。本文將系統闡述云原生架構的核心設計原則、支撐其實現的典型技術棧,并重點剖析在云原生環境下數據處理與存儲服務的演進與實踐。
一、 云原生架構的核心設計原則
云原生架構的設計遵循一系列關鍵原則,以確保應用能夠充分發揮云的優勢:
- 微服務化與服務自治:將單體應用分解為一組松耦合、獨立部署、可獨立擴展的細粒度服務。每個服務圍繞特定業務能力構建,擁有自己的數據存儲和技術棧,通過明確定義的API(通常是RESTful或gRPC)進行通信。
- 聲明式API與自動化:通過聲明式的配置(如YAML文件)描述系統期望的狀態,而非編寫指令性腳本。平臺(如Kubernetes)的控制器會持續對比實際狀態與期望狀態,并自動執行調整以達成一致,實現了部署、擴縮容、修復等操作的全面自動化。
- 彈性設計與容錯性:系統被設計成能夠容忍組件故障。通過健康檢查、自動重啟、熔斷器、限流、負載均衡和優雅降級等模式,確保局部故障不會導致整個系統崩潰,并能快速自我恢復。
- 可觀測性:系統應具備完善的監控、日志記錄、追蹤和告警能力。通過指標(Metrics)、日志(Logs)和分布式追蹤(Traces)三大支柱,提供對系統內部狀態和行為的深度洞察,以便于快速診斷問題、優化性能。
- 持續交付與DevOps文化:通過CI/CD(持續集成/持續部署)流水線,實現代碼從提交到生產環境部署的快速、可靠、自動化流程。這要求開發與運維團隊緊密協作,共享工具鏈和責任。
二、 支撐云原生的典型技術棧
一系列開源技術共同構成了云原生的技術基石:
- 容器化與編排:
- Docker:作為標準的容器運行時,實現了應用及其依賴的打包與隔離。
- Kubernetes (K8s):成為容器編排的事實標準,負責容器的自動化部署、擴縮容、服務發現和負載均衡,是云原生應用的“操作系統”。
- 服務網格:
- Istio, Linkerd:在服務間通信層(通常稱為數據平面)之上引入一個專用的基礎設施層(控制平面),以非侵入方式處理服務間流量,提供強大的流量管理(如金絲雀發布、故障注入)、安全(mTLS、策略)和可觀測性能力。
- 無服務器計算:
- Knative, AWS Lambda, Azure Functions:進一步抽象基礎設施,使開發者只需關注函數或應用邏輯。平臺按需分配資源,按實際使用量計費,實現極致的彈性與成本優化。
- 不可變基礎設施與GitOps:
- 將基礎設施(包括服務器、網絡配置)定義為代碼,并通過版本控制系統(如Git)進行管理。任何變更都通過提交代碼發起,由自動化流程應用到環境,確保環境的一致性和可追溯性。
三、 云原生環境下的數據處理與存儲服務
云原生理念深刻改變了數據處理與存儲服務的構建和使用方式:
- 存儲服務的云原生演進:
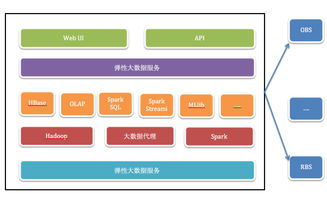
- 對象存儲作為通用數據層:如Amazon S3、Google Cloud Storage、MinIO等,因其無限的擴展性、高耐用性和通過HTTP API訪問的便捷性,成為云原生應用存儲非結構化數據(如圖片、日志、備份)的首選。
- 云原生數據庫與有狀態服務:傳統數據庫正在“云原生轉型”。一方面,云服務商提供托管的、與Kubernetes集成的數據庫服務(如Amazon RDS on Kubernetes)。另一方面,出現了許多為云原生環境從頭設計的數據庫,如CockroachDB(分布式SQL)、TiDB(HTAP)、Vitess(MySQL水平分片管理),它們天然具備彈性伸縮、高可用和容災能力。
- StatefulSet與Operator模式:Kubernetes的StatefulSet控制器為有狀態應用(如數據庫、消息隊列)提供了穩定的網絡標識、持久化存儲和有序的部署/擴縮容管理。Operator模式則通過自定義資源(CRD)和控制器,將特定應用(如PostgreSQL, Elasticsearch)的運維知識編碼為軟件,實現復雜有狀態應用的自動化生命周期管理。
- 數據處理的流批一體與實時化:
- 流處理框架:Apache Kafka(消息隊列/流平臺)與Apache Flink、Apache Spark Streaming等流處理引擎結合,構成了實時數據管道的核心。它們在Kubernetes上原生運行,能夠彈性處理連續不斷的數據流。
- 批處理與工作流編排:Apache Airflow、Kubeflow Pipelines等工具用于編排復雜的數據處理工作流(ETL/ELT),可以方便地在K8s上調度任務,管理依賴。
- 數據湖與湖倉一體:在對象存儲基礎上構建的數據湖,結合Delta Lake、Apache Iceberg、Apache Hudi等表格式,提供了ACID事務、模式演進等能力,向著“湖倉一體”架構演進,統一了數據存儲與分析。
- 數據服務的關鍵考量:
- 數據本地性:計算應盡可能靠近數據以降低延遲和成本。K8s調度器可通過節點親和性等策略,將數據處理任務調度到存有數據的節點附近。
- 彈性與成本:數據處理服務應能根據負載自動擴縮容,并在空閑時縮容至零以節省成本。這要求存儲與計算解耦,并采用按需付費模式。
- 多云與混合云數據管理:為避免廠商鎖定并滿足合規要求,設計需考慮數據的可移植性。使用開源標準、容器化的數據服務以及抽象層(如數據虛擬化),有助于構建跨云一致的數據體驗。
###
云原生架構通過其設計原則和強大的技術生態,正在重塑現代應用的建設方式。在數據處理與存儲領域,這一變革體現為服務的容器化、彈性化、智能化和API化。成功實施云原生數據戰略,不僅需要采納新技術,更需要將自動化、可觀測性和持續改進的DevOps文化貫穿于數據生命周期的始終。隨著Serverless數據服務和AI/ML工作負載的深度集成,云原生數據架構將變得更加智能和自治,持續驅動業務創新。