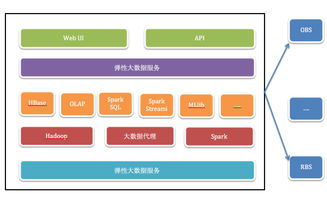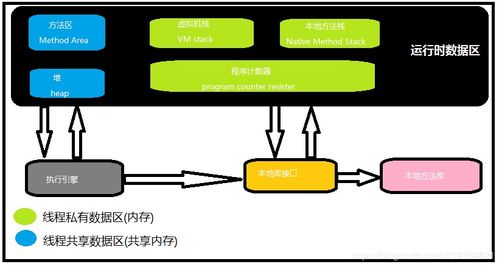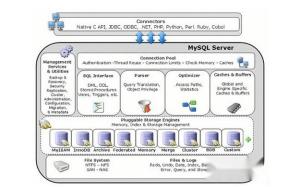
數據庫引擎是現代信息系統的核心組件,它負責高效地管理和操作數據,為各類應用提供可靠的數據處理及存儲服務。作為數據庫管理系統的“心臟”,數據庫引擎的性能和功能直接決定了數據處理的效率、安全性和可擴展性。
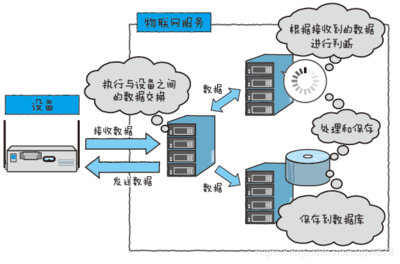
數據處理服務是數據庫引擎的核心功能之一。這主要包括對數據的增、刪、改、查(CRUD)操作,以及更復雜的查詢優化、事務處理和并發控制。高效的查詢優化器能夠解析用戶請求,選擇最優的執行路徑,從而快速返回結果。事務處理機制(通常遵循ACID原則——原子性、一致性、隔離性、持久性)確保了在多用戶并發訪問時數據的完整性和可靠性。例如,在銀行轉賬場景中,數據庫引擎必須保證扣款和入賬兩個操作要么全部成功,要么全部失敗,避免數據不一致。
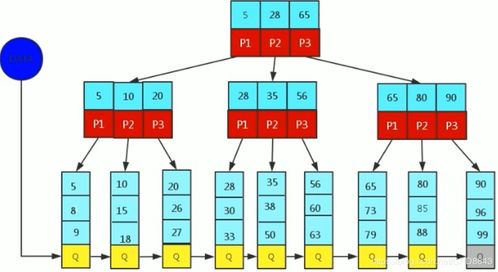
在存儲服務方面,數據庫引擎負責數據的物理存儲、索引管理和數據恢復。它通過精巧的數據結構(如B+樹、LSM樹)和組織方式,將數據持久化到磁盤等存儲介質中,同時利用索引大幅加速數據檢索。存儲引擎的設計需權衡讀寫性能、空間利用率和數據持久性。例如,一些引擎采用寫前日志(WAL)技術,在數據寫入前先記錄日志,確保即使在系統崩潰后也能恢復數據。現代分布式數據庫引擎還支持數據分片、復制和跨節點一致性協議,以提供高可用和可擴展的存儲服務。
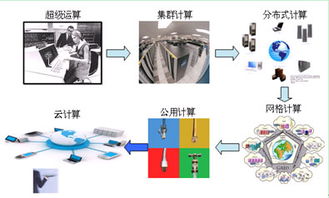
隨著技術的發展,數據庫引擎不斷演進,出現了適應不同場景的多種類型。例如,聯機事務處理(OLTP)引擎擅長高并發、短事務的讀寫操作,而聯機分析處理(OLAP)引擎則針對復雜查詢和大規模數據分析優化。內存數據庫引擎將數據主要駐留在內存中,實現極低延遲;而時序數據庫引擎則為時間序列數據提供了高效的存儲和查詢支持。云原生數據庫引擎更是充分利用云基礎設施,實現彈性伸縮和全局分布。
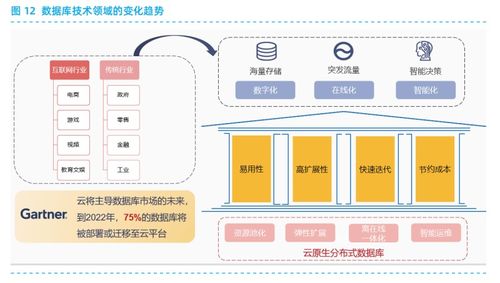
數據庫引擎通過其強大的數據處理和存儲服務,支撐著從企業核心業務到互聯網大規模應用的方方面面。理解其工作原理和特性,對于設計和構建高效、可靠的數據驅動型系統至關重要。隨著人工智能、物聯網等技術的融合,數據庫引擎將繼續向智能化、自適應和一體化方向發展,以應對日益復雜的數據挑戰。