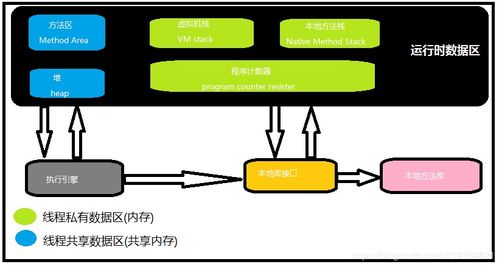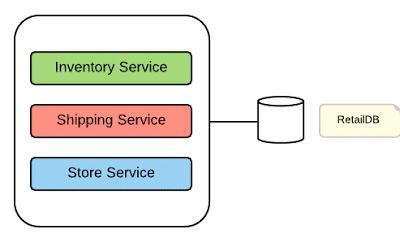
在當今快速迭代的軟件開發環境中,微服務架構以其靈活性、可擴展性和獨立性,已成為構建復雜應用的主流選擇。本系列文章將深入探討微服務從設計、發布到運維的全過程。上篇將聚焦于微服務架構的基石——數據處理及存儲服務,解析其核心挑戰、設計原則與最佳實踐。
一、微服務數據管理的核心挑戰
與傳統單體架構集中式數據庫不同,微服務架構倡導“每個服務擁有其專屬數據庫”。這一原則帶來了數據自治、技術異構等優勢,但也引入了新的復雜性:
- 數據一致性:跨服務的事務如何保證?經典的ACID事務在分布式環境中變得異常困難。
- 數據查詢:如何高效地執行需要關聯多個服務數據的查詢?
- 數據同步:服務間的數據如何可靠地同步,以支持業務邏輯?
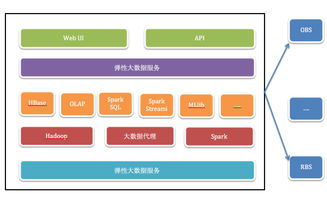
二、數據存儲模式與選型策略
為不同服務選擇合適的存儲技術是成功的關鍵。應遵循“根據用途選擇工具”的原則:
- 核心交易服務:對強一致性要求高,可選用關系型數據庫(如MySQL, PostgreSQL),利用其成熟的事務支持。
- 用戶會話與緩存:追求高性能與低延遲,鍵值存儲(如Redis)是理想選擇。
- 內容管理與全文檢索:文檔數據庫(如MongoDB)或專門的搜索引擎(如Elasticsearch)能提供靈活的 schema 和強大的查詢能力。
- 時序數據與日志:時序數據庫(如InfluxDB)或列式存儲(如Cassandra)在處理海量時間序列數據時效率更高。
三、解決分布式數據一致性問題
放棄分布式強一致性,擁抱最終一致性是微服務架構的常見設計。實現模式包括:
- Saga模式:將一個分布式長事務拆解為一系列本地事務,每個事務都有對應的補償操作,用于在失敗時回滾。
- 事件驅動架構(EDA):服務通過發布/訂閱領域事件進行通信。例如,訂單服務創建訂單后發布“OrderCreated”事件,庫存服務監聽該事件并異步更新庫存。這是解耦服務、實現數據最終同步的核心手段。
- 命令查詢職責分離(CQRS):將讀寫模型分離。寫模型專注于處理命令、更新狀態并發布事件;讀模型則訂閱這些事件,構建針對查詢優化的物化視圖。這極大地提升了復雜查詢的性能與靈活性。
四、實戰:構建一個可靠的數據管道
事件是微服務間通信的血液。構建一個高可靠的事件總線或消息隊列(如Apache Kafka, RabbitMQ)至關重要。
- 確保事件可靠投遞:采用持久化存儲,支持生產者確認和消費者確認機制。
- 實現事件溯源:將狀態變更記錄為一系列不可變的事件日志,這不僅是審計跟蹤,更是重建當前狀態和實現復雜業務邏輯的基石。
- 處理重復事件:網絡分區或重試可能導致事件重復,消費者必須實現冪等性處理。
五、數據存儲服務的部署與運維考量
- 數據庫即服務:考慮使用云托管的數據庫服務(如AWS RDS, Azure Cosmos DB),以減輕運維負擔。
- 配置管理:將數據庫連接字符串、憑證等通過配置中心或Secret管理工具進行管理,而非硬編碼。
- 數據遷移:將數據庫遷移腳本版本化,并集成到CI/CD流水線中,實現自動化、可回滾的 schema 變更。
- 監控與告警:密切監控數據庫連接數、查詢性能、磁盤空間等核心指標,并設置合理的告警閾值。
###
數據處理與存儲是微服務架構中最為復雜卻也最為關鍵的一環。通過精心設計數據邊界、采用合適的存儲技術、并利用事件驅動與最終一致性模式,我們可以構建出既健壯又靈活的系統。在下一篇中,我們將探討微服務的API網關、服務發現與通信機制,敬請期待。
(注:本文為實戰指南上篇,側重于概念、模式與設計原則。具體技術實現細節將結合具體技術棧在后續篇章或案例中展開。)