隨著人工智能技術的不斷發展,構建高效、專業的AI知識庫成為企業和開發者的重要需求。RAGFlow作為一個功能強大的開源工具,提供了從數據處理到知識存儲的完整解決方案,即使是零基礎用戶也能快速上手并精通。本文將詳細介紹RAGFlow的核心功能、數據處理方法、存儲服務機制,以及從入門到精通的完整學習路徑。
RAGFlow是什么?RAGFlow是一款基于檢索增強生成(Retrieval-Augmented Generation, RAG)技術的開源工具,旨在幫助用戶構建智能知識庫系統。它集成了數據預處理、向量化檢索和生成式AI響應功能,支持多種數據源,包括文本、PDF、圖像等。對于初學者來說,RAGFlow的安裝過程非常簡單,通常只需幾個命令即可完成部署,例如使用Docker容器化技術,無需深入編程基礎也能快速啟動。
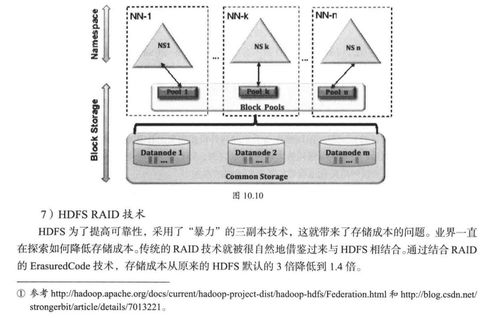
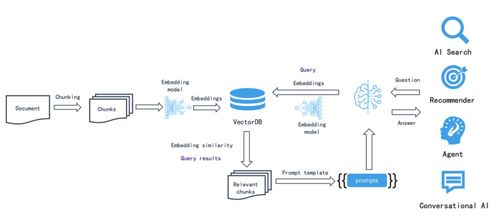
在數據處理方面,RAGFlow提供了強大的數據導入和預處理能力。用戶可以將本地文件、數據庫或通過API上傳的數據源導入系統。RAGFlow會自動進行數據清洗、格式轉換和內容提取,例如從PDF文檔中提取文本、識別圖像中的文字等。同時,工具內置了智能切分和向量化引擎,將文本數據轉換為高維向量,便于后續的語義檢索。這一步是構建知識庫的核心,RAGFlow通過優化算法確保數據處理的準確性和效率,即使面對大規模數據也能保持高性能。
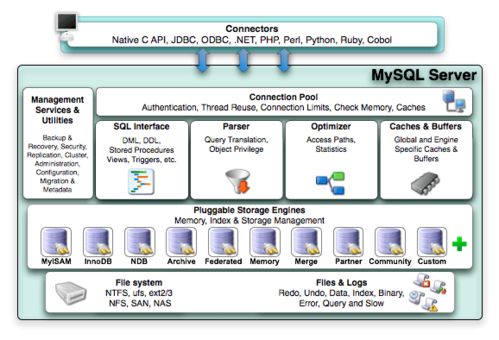
存儲服務是RAGFlow的另一大亮點。系統支持多種后端存儲選項,包括本地文件系統、云存儲(如AWS S3、阿里云OSS)以及向量數據庫(如FAISS、Milvus)。用戶可以根據需求選擇合適的存儲方案,確保數據的可擴展性和安全性。RAGFlow還內置了版本控制和備份功能,幫助用戶管理知識庫的歷史變更,防止數據丟失。通過RESTful API,用戶可以輕松集成RAGFlow到現有系統中,實現動態數據更新和實時查詢。
從零基礎到精通的學習路徑可以概括為以下幾個步驟:第一步,安裝和配置RAGFlow,熟悉其基本界面和功能模塊;第二步,學習數據導入和預處理技巧,包括如何處理不同類型的數據源;第三步,掌握向量檢索和生成模型的調優方法,例如調整相似度閾值和生成參數;第四步,深入存儲服務配置,學習如何優化性能和安全性;通過實際項目應用,如構建企業FAQ系統或智能客服知識庫,來鞏固技能。RAGFlow社區活躍,提供詳細的文檔和教程,用戶可以通過GitHub、論壇等渠道獲取支持和進階資源。
RAGFlow作為一個開源工具,降低了構建專業AI知識庫的門檻。通過本文的介紹,希望讀者能夠快速掌握其核心功能,從數據處理到存儲服務的全流程操作。無論是開發者還是業務人員,都能利用RAGFlow提升工作效率。趕緊收藏這篇文章,隨時參考,開啟你的AI知識庫之旅吧!